結局ブログ内検索はどうすればいいのか?
公開日 : 2007-09-28 06:44:40
テンプレートのところはツッコミ来るかなぁと思っていましたがまぁいいや! って書いたらやっぱり来ましたね。(o)さんは絶対にそこんとこ見逃しちゃぁくれません!
あと実験に関して付け加えると、やや公正さに欠けると思います。2.が「ブログ記事のメタデータ」モジュールのみ外した状態になっているのは比較上問題があります。利用するテンプレートの個数が異なりますから。それなら最初からflatteningしたテンプレートを使って比較すべきです。
たしかにモジュール読み込む時間分不公平でしたごめんなさい。
引き続きブログ(サイト)内検索を考える
「検索」についてはあれこれこれまでもやっていて、このブログにはHyper Estraier入れて、エントリーの保存時にインデックスを更新するプラグインを書いて利用してるので(出力の方はPHPにしてて起動のストレスもあんまりなくて)速度的には問題ないと感じてるのですが、皆がみんな導入出来るわけでもないわけで。
今週2本検索プログラム書いてみました。まだまだチューニングできるかと思うので もうちょっと何とかなったら公開しますね。
結局、検索に対する要求をmt-searchが満たせない(とWeb屋としての僕が思う)のは、
- 表示件数はともかく、何件マッチしたかが知りたい
- せめてページ送りができると嬉しい
- 検索語がハイライトとかできるといいな
- 検索結果の表示順にキーワードの出現頻度とかを考慮して欲しい
- HTMLタグまで検索に含まれるのはどうにかして欲しい
- 1ページにある程度の件数は欲しい
* 「結局ブログ内検索はどうすればいいのか?」Googleを使えってのはとりあえず考えないこと前提で (話がそれまくるので) 。
最後の話については、例えば(僕の知っている)視覚障害者の人は「ページ内検索」を良く使います。(cmd(ctrl)+F)で検索結果ページに対してページ内検索をかけて欲しい情報を探して移動するような使い方。
こういうことを考えると、ページ送りがあるにしても1ページにある程度の件数が欲しくなります。マッチするページが多ければ多い程。
で、もちろんmt-searchはタグ検索とか色々な役割を担っていてこれはこれで必要な機能を実現するために必要なものですが、(o)さんもご指摘の通り相変わらずふざけるなってくらい遅いです
ということなので、検索については案件毎に作ったりしていたのです。
で、今回MT::Objectのサブクラスを作ってテーブルを拡張してたりすると、そのテーブルがmt-serarchでは反映されてくれないということで(当たり前なんですけど、毎回オリジナル検索作るのも馬鹿げてると思ったので)汎用的なのを作ってみました。
結局、(MTにおける)サイト内検索の速度ってのは
- PerlCGIの起動の速度の問題
- 純粋な検索速度の問題
- テンプレートの再構築速度の問題
- データの転送とブラウザのレンダリング速度の問題
の4つの要素が絡むのかと思うわけですね。
1つめはFastCGI(mod_perl)かPHPを使うことで改善されます。問題は2番目と3番目かな。あと4番目もMT4のデフォルトテンプレートだと「ブログ記事のメタ情報」以前に、エントリーの本文とか(貼付けてある画像も表示されるし)これ全て検索結果に必要? って思うものが含まれています。もちろん、タグでの絞り込みとかにはいいんでしょうが。
さて、今回は2つめの件、つまり純粋に高速検索を実現するにはどうするかを考えてみました。
方法1. mt-searchと同じくループで回してマッチング
検索すべき文字列を一つのテーブルに放り込む。その際にHTMLタグは削除してしまう。但し画像のALT属性とかは検索対象にするようなフィルターを噛ましてから放り込む。
後は普通にループでマッチングを調べる。但し正規表現でなくindex関数を使って文字列が含まれるかどうか調べる。
最大検索数は設けるものの、その件数に達するまではループさせてページ送りを実装する。ここが一つの問題で、マッチした件数を調べるためにループを継続しないといけないのです。なぜなら「この文字列を含むレコード数」を簡単に調べる方法が現状のMTでは無いから。結局MySQLとかでLIKE検索した方が圧倒的に速いのです。
ただ、経験上ループ自体は(対象エントリーが数百であれば)そんなに時間かからないと感じているので、まぁやってみようかと。
あと、高速化のために、テーブルには表示用のデータ(ページの概要, メタデータとか)を一緒に保存しているので、ループでマッチすると同時に検索結果用のデータも取得できる。
体感速度は結構速いです。何よりも、環境を選ばないのがメリット。MTが動いていれば動作します。
方法2. 形態素解析で分かち書きして検索インデックスを作る
テーブルに放り込むところは方法1をベースにして、検索対象のテキストを mecab で分ち書きして記号や助詞助動詞、非自立とか不要そうなものを除いてデータベースに入れる。テーブルには単語とその出現回数、エントリーのID等や更新日(無駄なインデクシングを避けるため)を入れておく。
例えばMT4インストール後に自動的にできるエントリーを分かち書きして不要なものを除いた結果はこんな感じ。
Movable Type 4 0 ようこそ この ブログ 記事 Movable Type 4 インストール 完了 時 システム 自動的 作成 ブログ 記事 新しく MT 4 管理 画面 早速 ブログ 更新
インデクシングする時は英文字は小文字にする(MySQL環境だとMTのPerl APIから検索する時に区別してくれないようなので、数があわなくなる)。
各ワードと出現回数はこんな感じになる。
| 語 | 出現回数 |
|---|---|
| mt | 1 |
| 記事 | 3 |
| システム | 2 |
| インストール | 2 |
| ブログ | 4 |
| 作成 | 1 |
| 完了 | 2 |
| 画面 | 1 |
| type | 2 |
| 自動的 | 1 |
| movable | 2 |
| 更新 | 1 |
| 管理 | 1 |
| 新しく | 1 |
| この | 2 |
| 早速 | 1 |
| 4 | 3 |
これに、更新日とかオブジェクト(エントリーのIDとか)を一緒に保存。こうしておけばマッチするエントリーの数は
my $match = Itasenpara::Itasenpara->count( { blog_id => $blog_id ,
keyword => $query } );
で得られるし、トータル数を得ておいてからオフセットとリミットを指定して検索できるから必要な数だけロードしてあとはページ送りを実装してやることができるよね。
* Object名はItasenpara(イタセンパラ) にした! Namazuにインスパイアされて!?
my @entries = MT::Entry->load( blog_id => $blog_id, {
'join' => [ 'Itasenpara::Itasenpara', 'object_id',
{ keyword => $query },
{ 'sort' => 'word_count',
direction => 'descend',
unique => 1,
offset => $offset,
limit => $limit, } ]
});
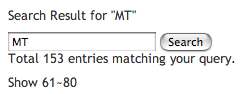
![]()
もちろんいいことばかりじゃないけど、メリットは単語の出現回数順に表示できるところと高速なところ。デメリットは再構築に時間がかかるところ。但し一回全再構築してしまえば更新日付をチェックしてインデクシング不要ならスキップするようにしたのでまぁ高速な検索のトレードオフというか、今気づいたけどそれこそインデクシングはバックグラウンド処理ですればいいんだ、そうだよね、きっと。
あとは複数ワードのAND検索とかOR検索だけど、素直にSQL書いた方が速いような気がしてます。ってか、もうちょっとスピード出るかと思った...
mecabをインストールする時点でHyper Estraierのパターンと同じく導入に条件が入る。だからこそ「方法1. mt-searchと同じくループで回してマッチング」のような方法もあわせて選択できるようにしておくのがいいかな、と。Namazuだったらインストール済みサーバーも多いんだけど、UTFのことがあってインデクシング用プラグインとか書く気が起こらないんだよなぁ。
追記: 結論としては、2の方法でインデックスを作成しておいてPHP/Perl(FastCGI)で検索、という方向が良いように思う(分かち書きが無理な場合は1の方法+PHP検索)。っていうかさっきはじめてPHP対応のMTプラグイン書いてみて、何とかいけそうだなと思ったので。
